![[DL] Ensemble, Matrix Confusion and Linear Regression](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FAiu9s%2FbtqUtpfkCUo%2Fjqd0d1UnoWWH5IU7M69Ay0%2Fimg.png)
Ensemble에서 가장 대표적인 알고리즘은 Random Forest이다.
Bagging => Boostrap Aggregation

Random Forest에서 Random이 붙은 이유는 DicisionTree를 만들때 랜덤하게 특징을 뽑아와서 만들기 때문에
Random이 붙는다.
부스팅종류는 여러가지가 있는데 그중에
1. Ada 부스팅
2. Gradient 부스팅
이 대표적이다.
RandomForest에서 하이퍼 파라미터에는
1. n_estination 은 몇번 돌릴지에 대한 값을 넣는 인자값이다. 디폴트 값이 100이다.
2. max_features = 특징들 예를들어 10을 지정하면 30개가 있으면 10개만 랜덤으로 돌려가면서 뽑아온다는 의미이다.
(디폴트 = ) 만일, feature갯수와 같다면 같은 DT가 나온다.
값이 크면 효과적으로 결과가 나오지 않는다, 이유는 데이터가 모두 같을수도 있기때문이다.
3. n_jobs = 는 cpu의 갯수를 지정하는 인자값이다.
출처: https://u-n-joe.tistory.com/121 [JoE's StOrY]


이미지라면 gpu가 높아야한다.
하이퍼 파라미터 = Heuristic Value 이라고 한다.
알고리즘이 깊어질 수록 하이퍼 파라미터의 종류가 많아 진다.

차원이 높고 희소한 데이터라는 말은 = 특성이 많고 데이터가 없다는 뜻이다. 이럴땐 (리니어 리그레이션)을 사용한다

Accuracy_score를 사용했었는데 이젠 Matrix confusion을 사용해보자.
이걸가지고 모델의 정확도를 알 수 있다.

confusion Matrix를통해
1. Accuracy
2. precision
3. recall
을 알 수 있는데,
1를 알고, 2와 3이 어떻게 차이나는지만 정확하게 알면된다.
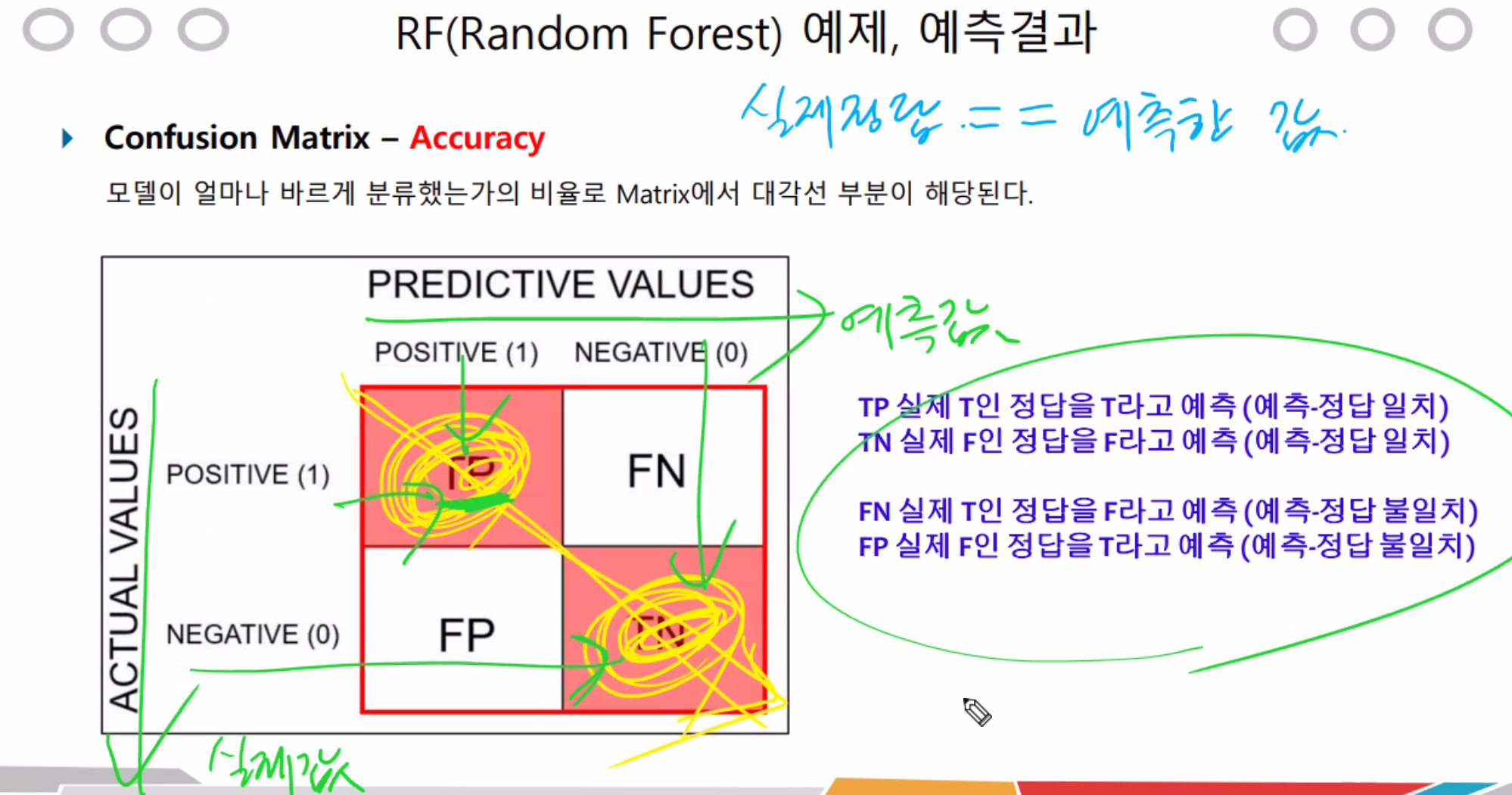
노란선이 Accuracy 부분이다.

빨간색 = Variance가 높다는거는 의존성이 높다는 것이다. overfitting이 심함.
파란색처럼 overfitting을 낮춰줘야한다.

Boosting


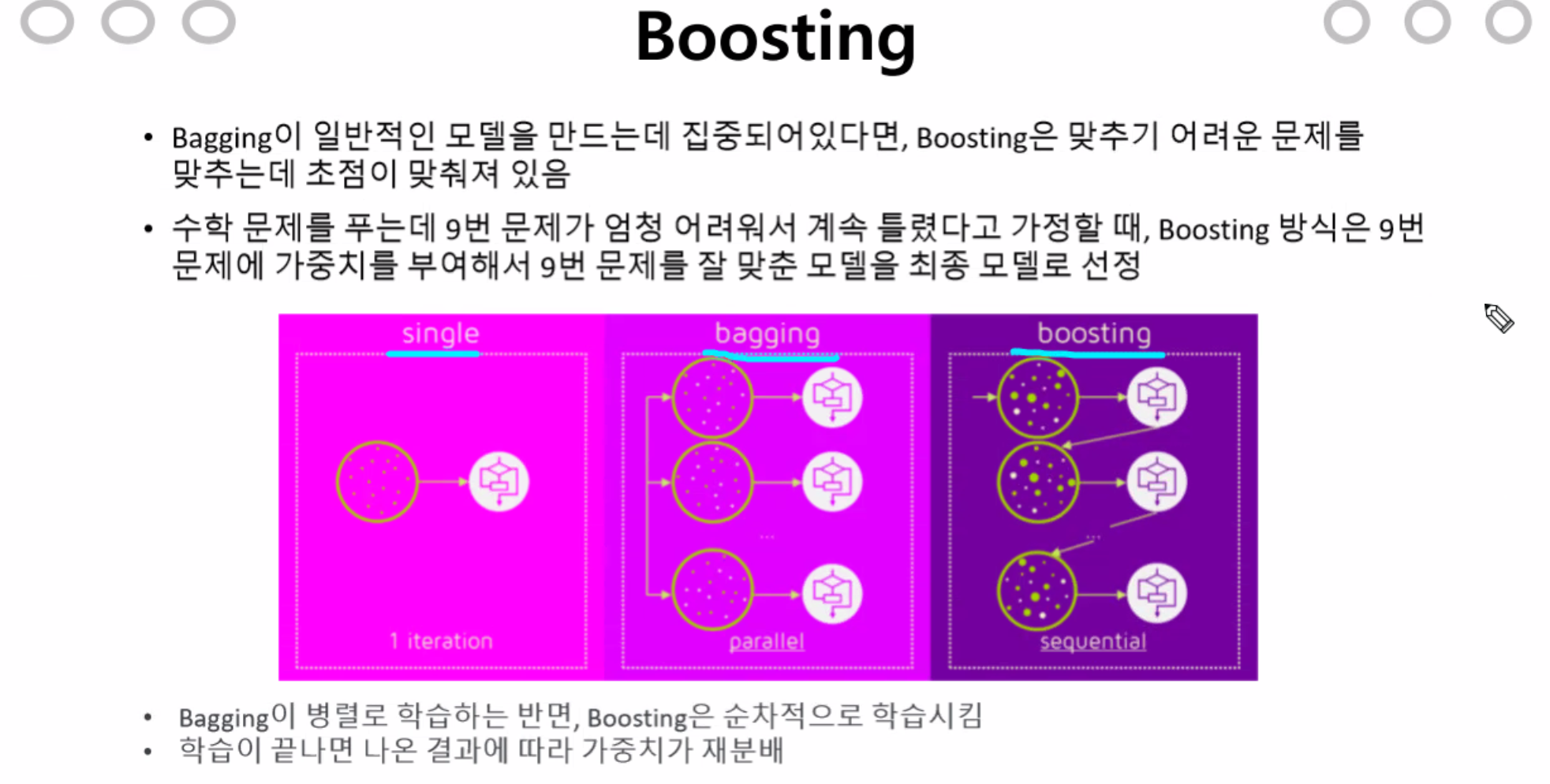
single = DT
bagging = RF
boosting = GradientBoost

잘못된 지점을 계산해 나간다. 예측을하고 성능평가를 해서 Confusion_Matrix를 통해 결과를 보고
학습해서 계속적으로 반영해서 잘못된 점을 성능이 높아질때 까지 나오게 한다.
즉 오답노트를 쓰는것처럼 계속 고치고 평가 고치고 평가를해서 점점더 Ac를 높히는데 목적이 있다.
메모리가 적어지므로, 학습 속도가 굉장이 빠르게 분류된다.

learning_rate는 학습속도를 조정하는 하이퍼 파라미터이다.
gradientBoosting에서 가장 중요한 하이퍼 파라미터이다.

Grid_Search 의 교차검증을 통해서
최적의 Cost와 gamma를 알 수 있다.
Hyper Parameter Tuning 튜닝하는법
1. 그리드 맵을 그린다.
현업에서 주로 사용하는 방법

2. 계산값이 얼마나 나오는지 확인한다.

완변한 하이퍼 파라미터 튜닝하는법
AutoML(인공지능이 최적의 하이퍼파라미터값을 직접 찾도록 도와주는 함수이다.) - 구글, 아마존에서 주로 사용한다.
문제점 - 사람이 찾는것보다, 성능이 안좋게 나온적이 있다. GPU가 최소 100개여서 대기업바께 사용을못하지만
최근에 성능이 높다는 결과를 도출해냈다. 지금 개발중임.


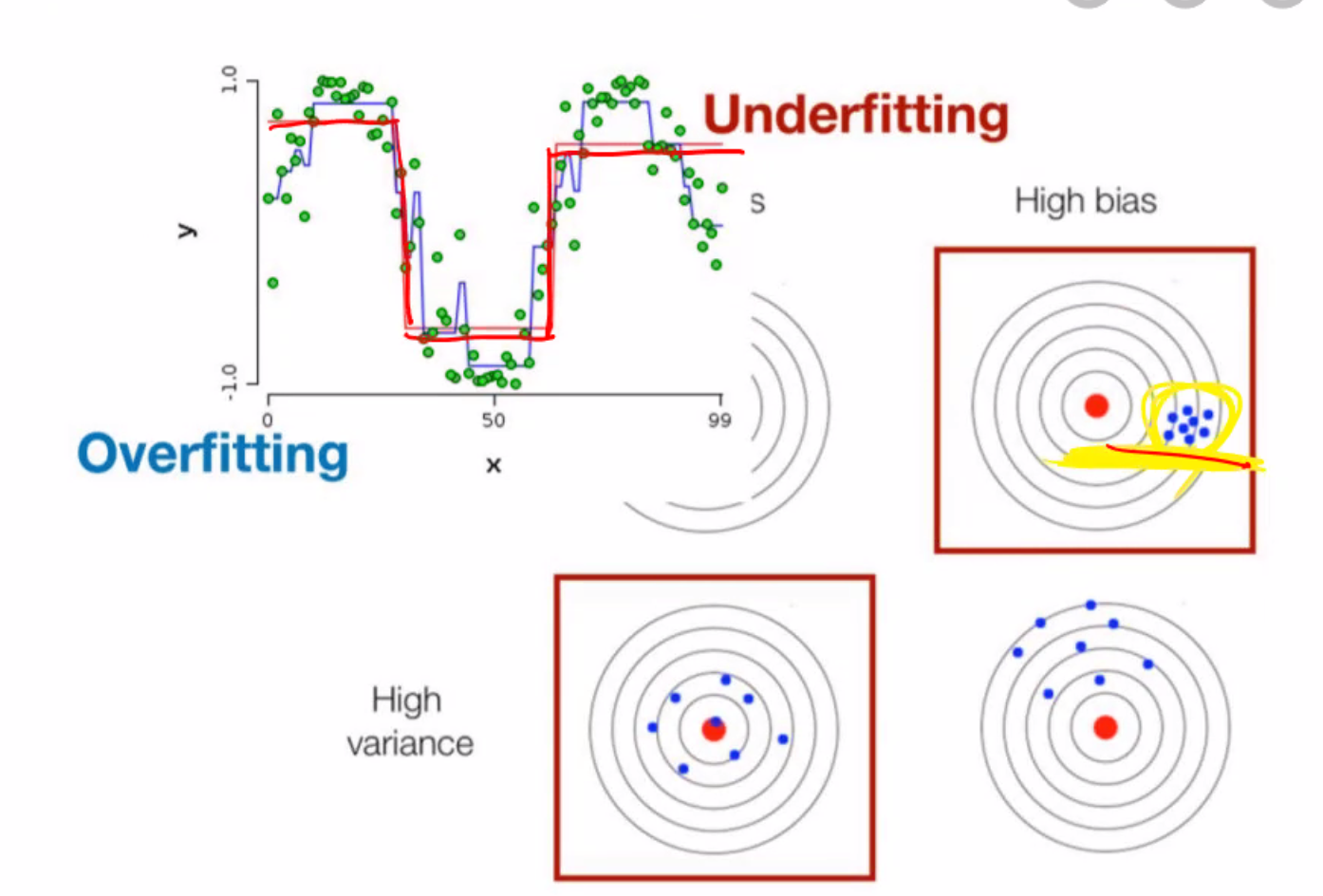
Bias가 높으면 Underfitting이 높다. = 학습시간이 적거나, 데이터가적거나, 즉 학습량이 낮은경우 Underfitting
Variance가 높으면 Overfitting이 높다. = 학습을 너무 많이해서, 의존해서, 외워버린경우, 일반성이떨어지고, 추상성이떨어진다. >> Overfitting
Tradeoff == 반비례하다, 서로 다르게움직인다. Bias와 Variance는 Tradeoff관계이다.

2번같은 경우는 underfitting으로 학습 시간을 늘려야한다. bias의 경우 데이터는 응집되어있지만
4번은 데이터의 양을 늘려야한다. 왜냐면 타겟을 못맞춤.
3번은 학습시간이 너무 과한 경우이다. variance의 경우이다.


하이퍼 파라미터를 art라고 표현한다.

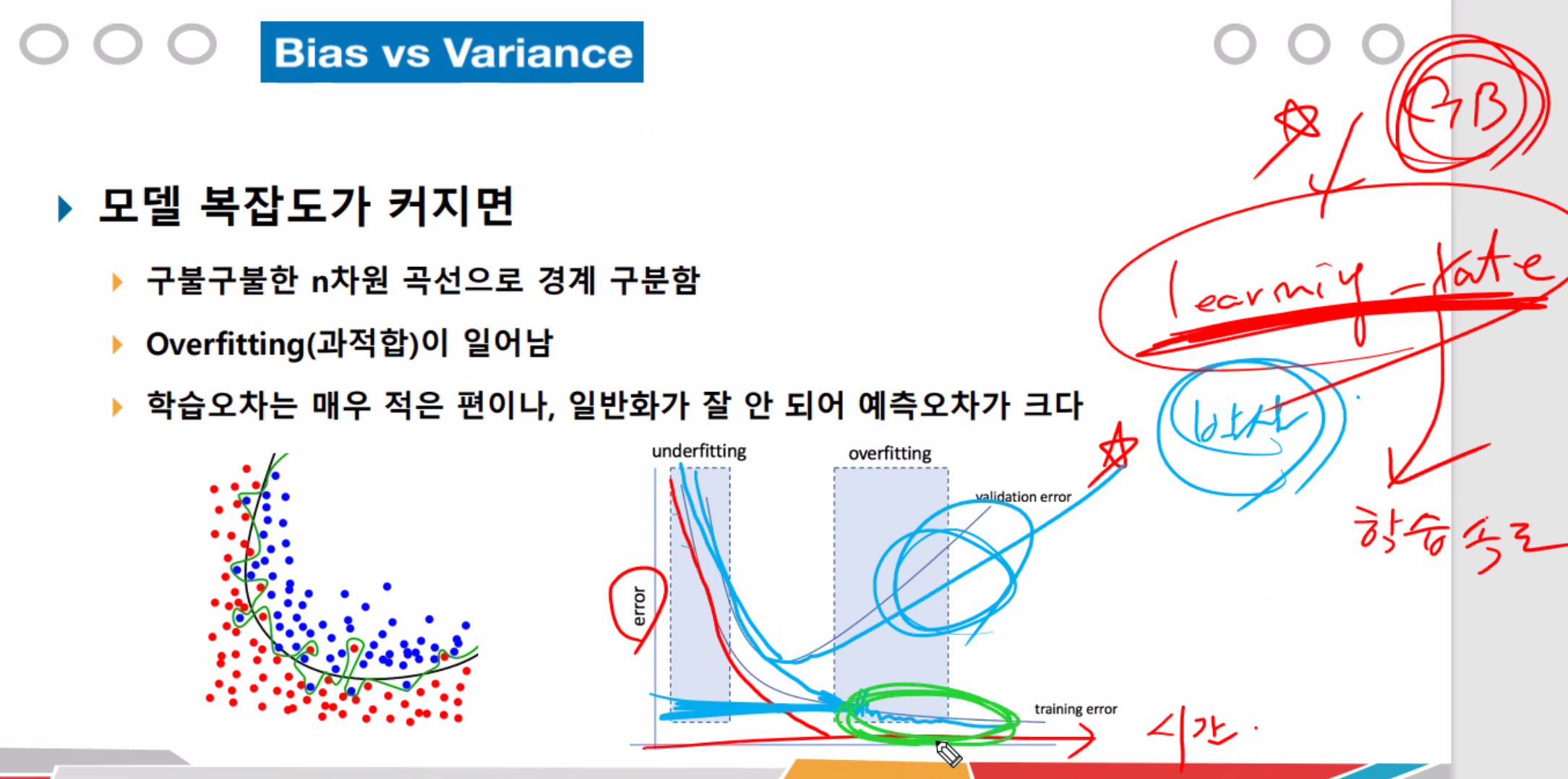
learning_rate(학습속도)을 0.001~0.00001처럼 세밀하게 줘야한다.
error가 낮은 지점에 잘 맞춰줘야 이후로 overfitting이 안난다.


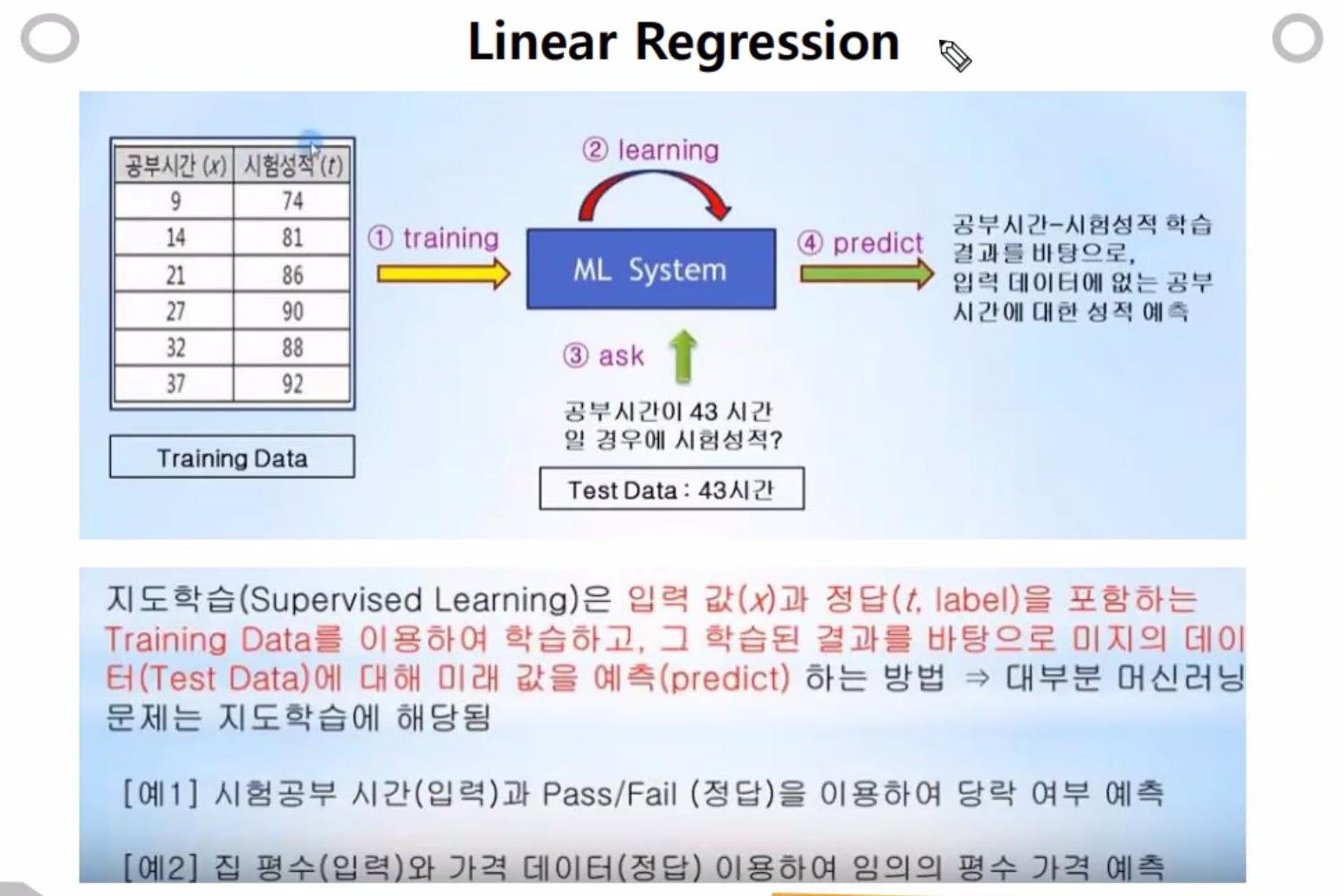
1차원이라서 소문자 x를 사용. input으로 공부시간을 넣고

분류모델은 fail/pass로 나뉜다... label으로 나온다~

Linear Regression은 회귀모델
Logistic Regreesion은 분류모델로 사용된다. (멀티 라벨 클레시픽케이션, 바이너리 클레시픽케이션으로 두종류를 나눌수 있다.)
모델을 설계할때 회귀,분류모델을 사용할 지 결정하고 분석에 들어가야한다.
독립변수는 연구자가 의도적으로 변화시키는 변수를 말한다
종속변수는 연구자가 독립변수의 변화에 따라 어떻게 변하는지 알고 싶어하는 변수를 말한다.



Hypothesis 는 y = wX + b라고한다.

H(x) = Hypothsis x 가설함수.
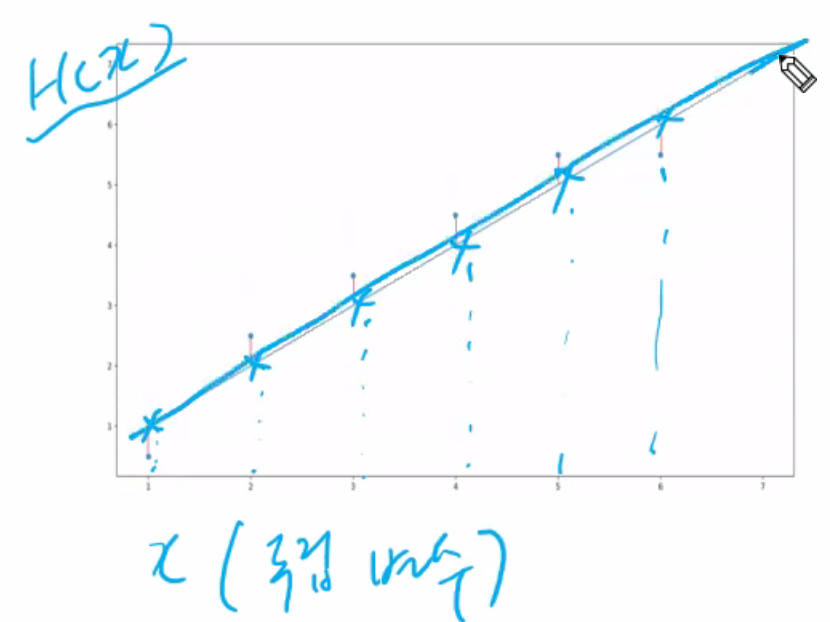
y = 1x + 1 으로 실제 값은 위 아래로 벌어진 만큼의 차이다. (파란선이 예측값임.)
가설 - 실제값 = 0에 가까울수록 예측을 잘 한 것임. cost(loss) function이다.
loss function의 값은 정확도라고 보면된다.

제곱을 하는 이유는
1. 오차의 범위에 가중치를 주기 위해서이다. >> 패널티 적용을 시키기 위해서이다.
2. 양수로 만들어 주기위해서 이다. >> 무조건 양의 값이 나와야 한다.
H(x)는 가설값 (파란점), y는 실제값 (빨간점)
잘 맞췄는지 확인하기 위해 가설값과 실제값을 빼준다.
(잘, 못했는지)정량화를 위해 loss function을 사용, 원리는 예측값에서 실제값을 빼준다. 하고 제곱한다. 양의수+패널티 부여하기위함
다 더한값의 평균을 시그마로 계산한다.


오차가 가장 작은 , cost값이 가장 작은 값을 말한다.
여기서 말하는 bias는 절편을 말한다.



w를 변경한다는 것은 기울기 값을 변경한다는 것이다.

w가 낮아 질수록 cost가 낮아지고 y는 0에 가까워진다. >> Accuracy가 증가한다.
기울기 변경은 미분, 수가 많으면 편미분을 사용한다.
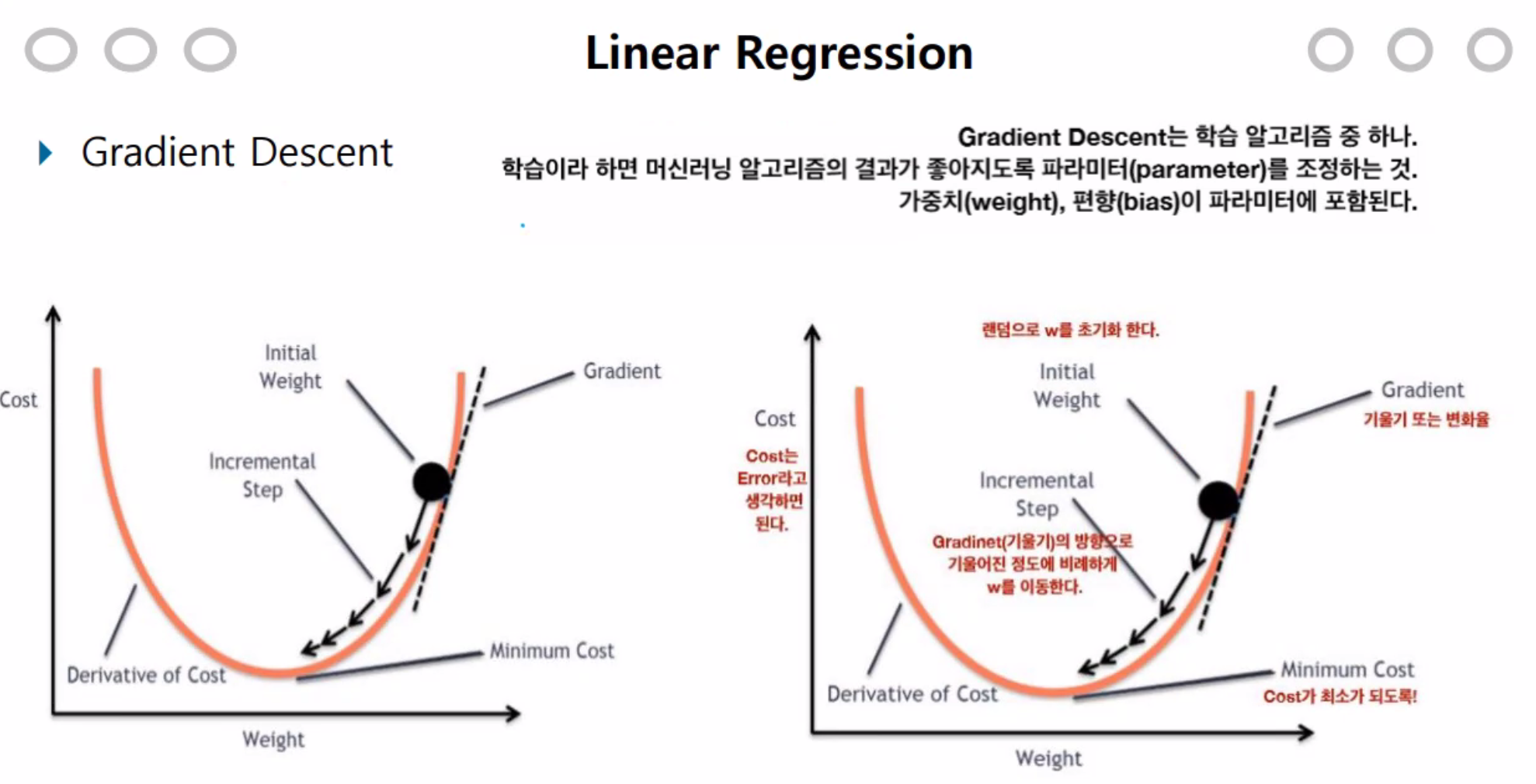

loss function으로 정확도를 알수 있고,
고도가 높다는건 loss가 크다. >> 예측을 잘 못한것. 고도를 낮춰야 한다.
낮추면 녹색선의 고도를 찍게되고, 더 낮춰서 또 낮은 값을 찾아낸다.

고도가 최소가 되도록 만들어야 한다. 0이되면 학습을 중단 시킨다. 그때까지 학습을 계속 시킨다.
경사하강법은 Cost function에서 Cost를 점점 낮추는데 목적이 있다. 낮아지면 그만큼 정확도가 상승되기 때문이다.

'workSpace > PYTHON' 카테고리의 다른 글
| [DL] Knowledge and Algorithm Overview (0) | 2021.01.27 |
|---|---|
| [ML] Collaborative Filtering (추천 협업 시스템) (0) | 2021.01.26 |
| [DL] SNN의 구조 및 분류와 회귀, 수식적 이해와 작동원리 (0) | 2021.01.23 |
| [DL] 딥러닝의 이해 (0) | 2021.01.22 |
| [ML] Entropy, impurity, gini impurity, Ensemble, Random Forest 설명 (0) | 2021.01.20 |