![[ML][DL] 전반적인 이해도 및 로직 설명, 자료](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FI1vaC%2FbtqTSTGBBGj%2FiJ846vyCsJe7KzL5MLVfi1%2Fimg.png)






PDF 파일 내용정리


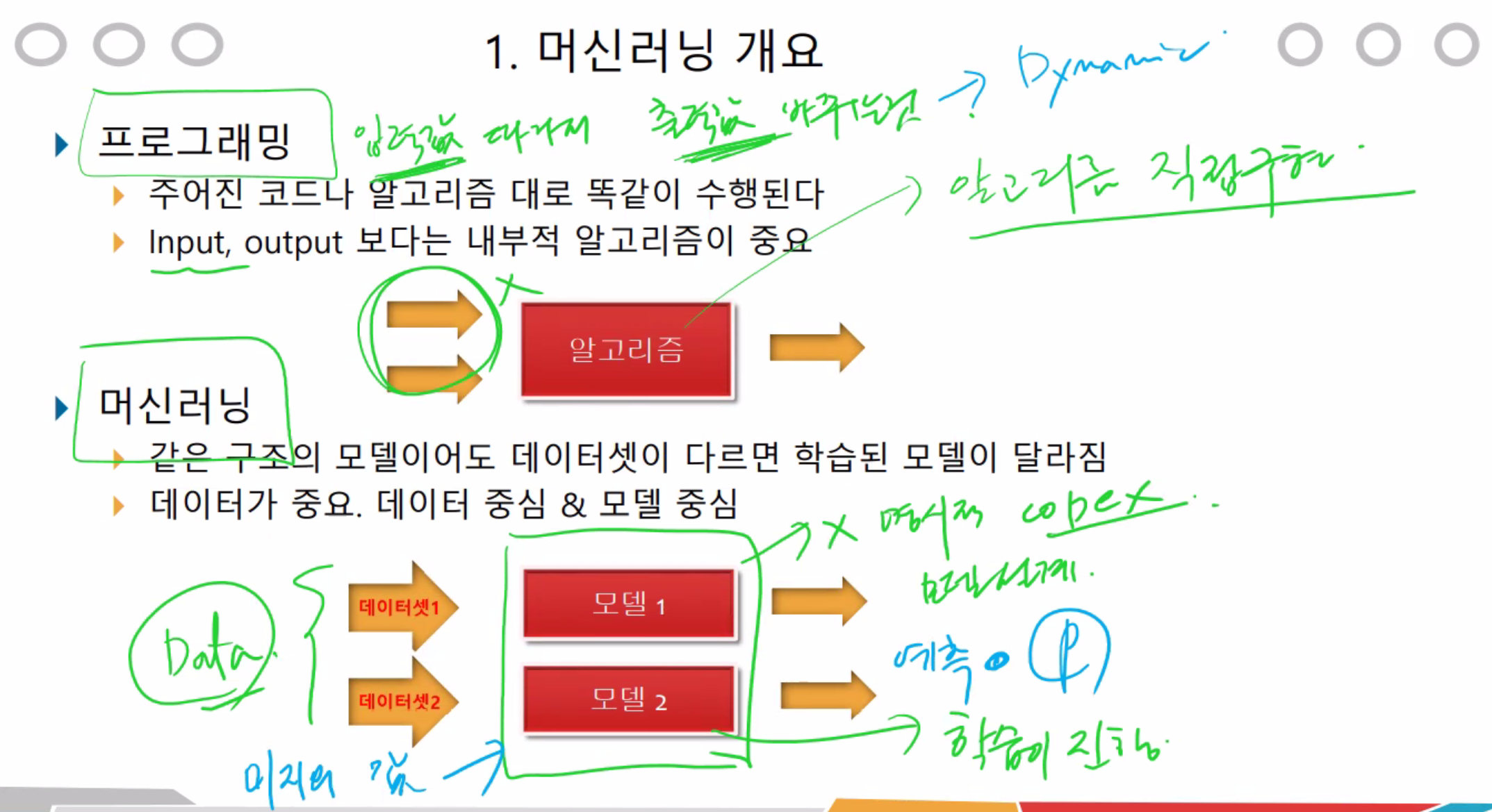
머신러닝은 모델과 같다고 볼 수있다.
1. 데이터 준비 (몇만개)
2. 모델설계 (데이터 학습) - 어떤 모델로 설계할지만 결정하고 데이터를 받아옴
3. 미지의 데이터를 넣음 (넣었을때 잘 학습되었나 확인)
4. 데이터를 모델에 넣었을때 올바른지 판단 (정확도 측정)
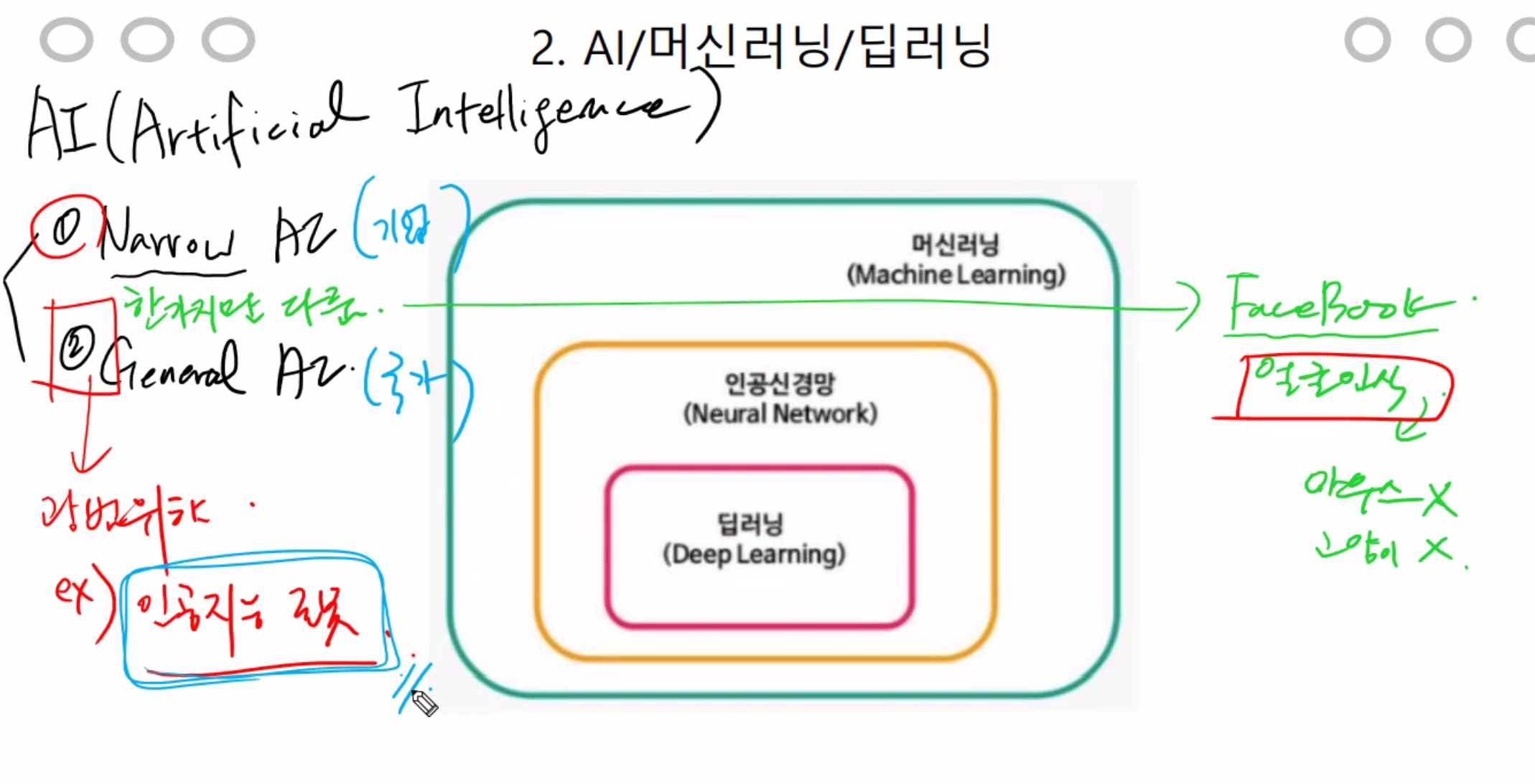
사용할 모델 4가지.

프로그래밍과 머신러닝의 차이점




비지도 학습과 지도학습
<공통점>
1. 데이터로 학습한다.
<차이점>
1. 정답의 유무 (비지도 = 유사성으로 판단한다.)
지도학습 = 머신러닝이 학습할때 답을 함께 제공해주는 것
비지도 학습 = 머신러닝이 학습할때 답을 제공하지 않고 그냥 학습하는 것
지도 학습과 비지도학습을 잘 이해하려면 머신러닝 학습을 어떤식으로 하냐는 것을 먼저 이해해야한다.
머신러닝은 일반적으로 아래의 절차로 학습을 진행한다.

머신러닝의 종류나 사항에 따라 명칭과 과정이 조금 다르지만 일반적으로 학습데이터를 준비하고 머신러닝 알고리즘이나 모델을 학습시키는 과정은 동일하다.
여기서 학습 시키는 방법에 대해서 지도학습과 비지도학습은 차이점이 크다.
지도학습
일반적으로 학습데이터를 속성, 정답 구조로 제공을하여 학습하고 머신러닝 모델이나 알고리즘은 학습데이터로 제공해준 속성에 따른 정답의 패턴을 학습하여 예측을 하거나 결과 값을 만들어 낸다.
지도학습은 학습데이터에 정답을 같이 제공하기 때문에 학습하는 과정에서 올바른 예측을 하고 있는지에 대한 평가가 어느정도 가능하다.
지도 학습으로 할 수 있는 경우는 정답이 있는 수를 예측하거나 예측할 데이터가 특정한 카테고리에 속하는 지를 판단하는 분류문제에 적당할수 있다.
예를 들어 학습 데이터를
[속성, 정답]
[1,2]
[2,4]
[3,6]
[4,8]
위와 같은 식으로 제공하여 학습하고 속성 값이 5일때 정답을 무엇일까? 를 예측하는 문제를 할 수 있다.
여기서는 5 x 2= 10 이기 때문에 10일것이다.
또한 아래와 같이 훈련데이터를 제공할 수 도 있을 것이다.
메일내용1, 스팸메일
매일내용2, 스팸메일아님
매일내용3, 스팸메일
속성을 메일 내용으로 구성하고 정답을 해당 메일이 스팸메일인지 여부를 제공하는 형태이다.
이것은 새로운 메일내욜을 제공했을때 해당 메일이 스팸메일이냐 아니냐를 판단하는 분류 문제로 생각할 수 있다.
비지도 학습
속성만을 학습데이터로 제공하여 머신러닝 모델이나 알고리즘을 학습 시키고 제공된 속성들의 패턴만 학습하여 예측을 하거나 결과 값을 만들어 낸다.
정답을 따로 제공하지 않고 속성만을 학습하기 때문에 학습하는 과정에서 결과 값이 어느정도 정확한지 측정하기가 용이하지 않다.
속성들만 제공하고 학습하여 결과를 만들어 내기 때문에 속성값만 가지고 패턴을 찾는 클러스터 문제에 흔히 쓸수 있다.
예를 들어서 훈련 데이터를
1개체의 속성 A , 1개체의 속성 B
2개체의 속성 A , 2개체의 속성 B
..N개체의 속성 A, N개체의 속성 B... 처럼
학습 데이터를 제공한후 개체의 A,B속성에 따른 어떤 패턴이 있는지 클러스터링을 군집된 집합들을 보고 새로운 데이터는 어떤 군집에 포함이 되는냐를 예측할 수 있을 것이다.


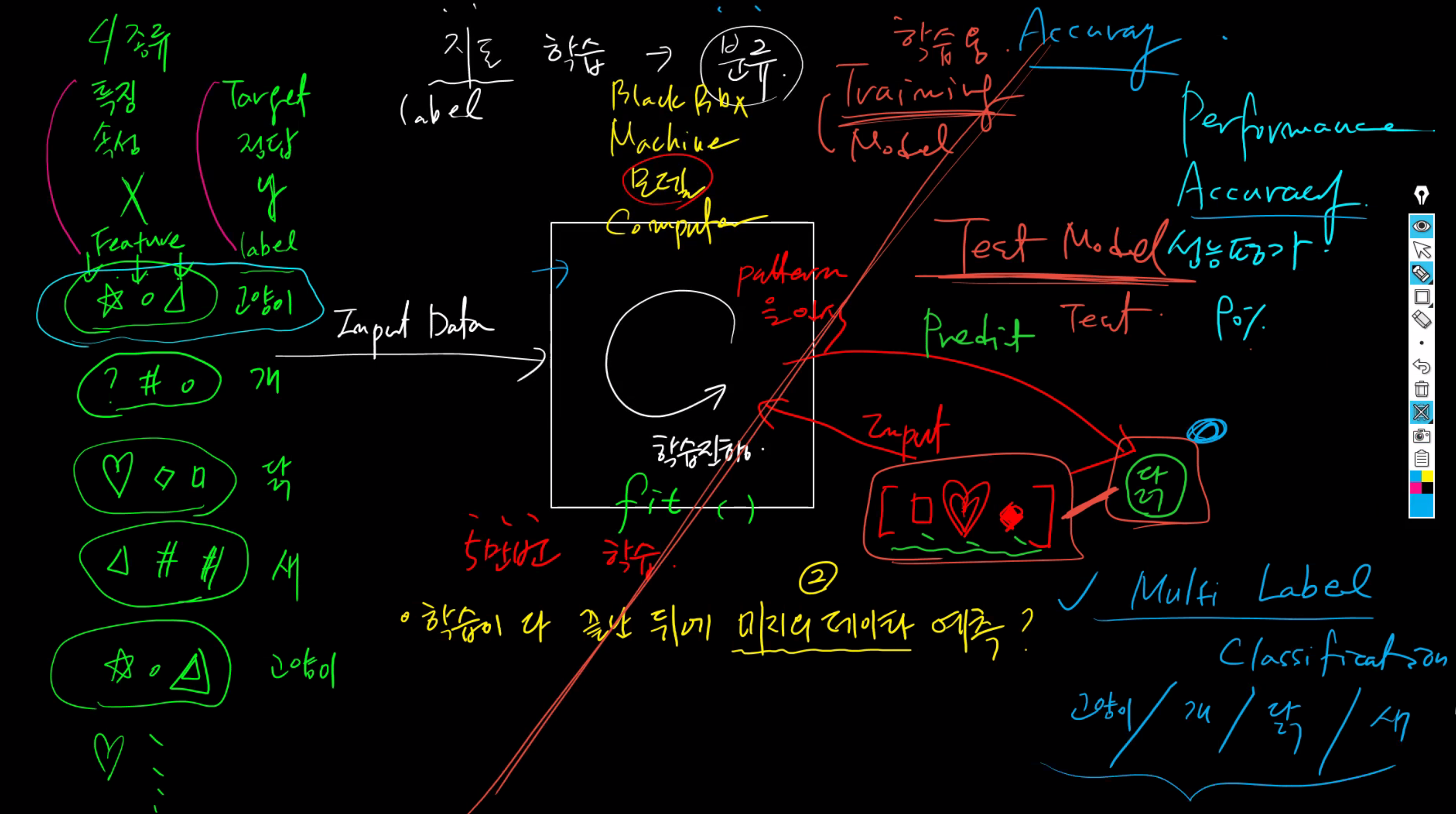

둘중의 하나
1. 바이너리 classification (둘중 하나)
2. 멀티 라벨 classification (여러개 중 하나)
수능으로 예시를 들면, 시험을 보기전 학습을 해서 시험 결과를 알 수 있다.
이 처럼 학습형과 수능형이 있다.
수능점수가 낮으면 학습을 더 시켜서 수능을 다시 볼수 있음. 80의 퍼포먼스가 나오면 출시...
(아래그림 참조)


회전시키거나, 명암, 부분적으로 자르고 다양한 자료를 넣어서 학습효과를 넣어줄 수 있다. 다양하게 넣어야 학습률이 높아짐.
2가지의 모델 (트레이닝 모델, (인퍼런스,테스트) 모델이 있다.)


<트레이닝의 학습법> (윗 그림 참조.)
back에서 중요도 값을 낮게 해서 업데이트후 다시 forward로 진행한다.
이와같이 계속적으로 반복해서 loss를 낮게해서 정확도를 높힌다.
테스트에서는 한번만 진행됨.

트레이닝에서 100이 나오면 안됨... 이유는 다 외워버린 증거(외워 버림)
궁극적인 목적은 테스트의 점수를 높혀야 한다.
overfitting을 줄이는게 목적이다. 즉 외워 버리는 것을 줄이는게 목크 적.
100을 찍을때는 실망 해야함. (외워버린 경우임.)

overfitting은 학습은 많이 했지만 트레이닝만 많이 해서 외워버린경우 테스트에서 잘 안나옴. (학습데이터에 편중될경우)
나의 데이터에만 너무 치중된 경우 overfitting이 된다.
낮출때는 추상화를 시켜야 한다.
underfitting은 학습량이 적어서 트레이닝에서 는 높게 나오지만 테스트에서는 낮게 나옴.
underfitting 과 overfitting이 낮게 나와야 좋은 performance를 낼수 있다.
학습할 데이터 셋

calsses가 단순하면서 많으면 accuracy가 좋게 나온다.
해상도가 높을수록 accuracy가 낮게 나온다.
데이터 셋 mnist와 cifar-10을 받아서 작업할 예정. or csv로.
머신러닝에서 이미지를 다룰때는 성능이 안나와서 딥으로 다뤄야 한다.
참고 자료
www.youtube.com/watch?v=KDrys0OnVho
www.youtube.com/watch?v=5wQ64XqQQhQ
'workSpace > PYTHON' 카테고리의 다른 글
| [ML] SVM - 지도학습 분류모델 실습 (0) | 2021.01.18 |
|---|---|
| [ML] SVM - 지도학습 분류모델 (0) | 2021.01.18 |
| [Pandas] 판다스 기초 상식 정리 및 함수 응용 3 - 네이버 영화 평점 분석 (0) | 2021.01.14 |
| [Pandas] 판다스 기초 상식 및 함수 정리 4 - pivot_table (0) | 2021.01.14 |
| [Pandas] 판다스 기초 상식 및 함수 정리 3 - groupby (0) | 2021.01.14 |