![[ML] SVM - 지도학습 분류모델](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FlNdYk%2FbtqTYRu90pi%2Fv9YDzXUm9OkTFvBuRTKyIK%2Fimg.png)
02_SVM_Classification.pdf
1.73MB
SVM(Support Vector Machine)
주로 분류할때 사용된다 classification
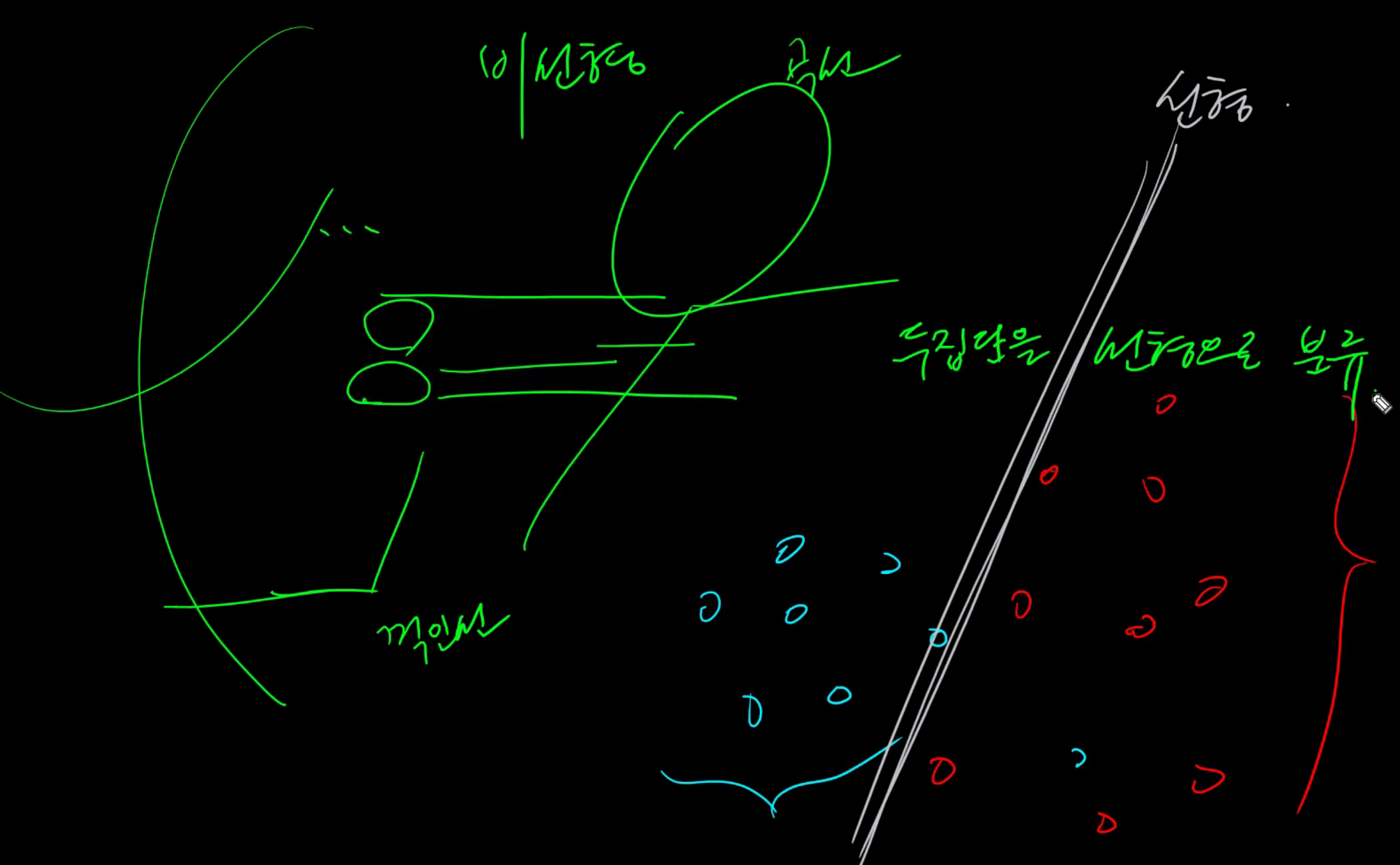
SVM은 선형으로 두 집단을 분류한다.



(왼)마진 좋게 아웃라이어 나옴 코스트 낮음 - 일반적임.
(오)마진 안 좋게 아웃라이어 안생김 코스트높음 - 오버피팅이 많이 나오는 경우이다

차원을 다르게 하면 선형으로 나눌수 있다.

코스트는 구별하는 선, 감마는 개별데이터마다 결정선을 지정하는 것에 초점을 둔다.
두 값 모두 커질수록 알고리즘의 복잡도는 증가한다.
overfit을 줄이는 것 사이의 균형을 잘 맞춰야 한다. (tip : 코스트만 기본 값으로 둔다 )

머신은 숫자만 인식한다.
SVM패턴
특징 1. 스스로 좌표를 설정한다.
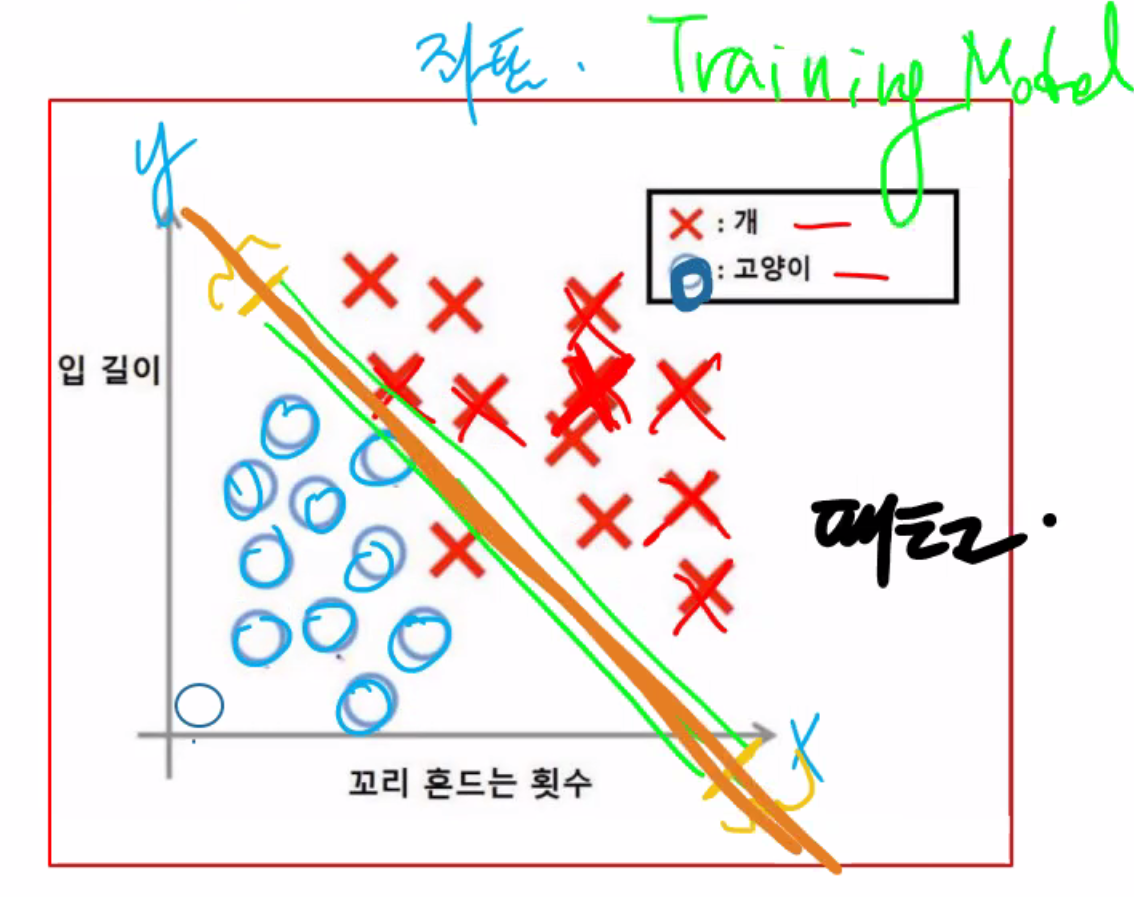




설명 : 특징이 많으면 많은 만큼 어렵다. accuracy가 낮게 나온다.
데이터 = 명확하지가 않음. 위의 데이터는 연관성이 없음.

'workSpace > PYTHON' 카테고리의 다른 글
| [Pandas][Numpy][seaborn] 2019년 서울 특별시 주유소 판매가격 분석 및 표 만들기 (0) | 2021.01.18 |
|---|---|
| [ML] SVM - 지도학습 분류모델 실습 (0) | 2021.01.18 |
| [ML][DL] 전반적인 이해도 및 로직 설명, 자료 (0) | 2021.01.18 |
| [Pandas] 판다스 기초 상식 정리 및 함수 응용 3 - 네이버 영화 평점 분석 (0) | 2021.01.14 |
| [Pandas] 판다스 기초 상식 및 함수 정리 4 - pivot_table (0) | 2021.01.14 |