![[DL] Linear Classification, Forward propagation, Full loss Function](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FejIuTx%2FbtqUL8Rvii4%2FMfZBhyYNmhFCAruh8oiR10%2Fimg.png)
Computer vision

기계의 시각에 해당하는 부분을 연구하는 컴퓨터 과학의 최신 분야이다.
인간이 시각적으로 할 수 있는 일을 기계가 그대로 하는 것이 목표이다.
결론 - 해당되지 않는 파트가 없다...
사물의 모서리는 각 물체의 명암이나, 색이 급격히 변하는 부분을 말한다.
명암, 모서리는 기울기를 말하며 미분을 말한다.
밝기의 기울기 = gradient
하지만 배경또한 같은 색이면 도출하기 힘들 것이다. 즉, 한계점이 있다......
그래서 나온게 CNN이다...

위 사진은 예전 초기 발명된 CNN로직이다.
얀르쿤, 제프리 힌튼(얀 르쿤의 스승), 조슈아 벤지오(자연어 처리) [얀르쿤 aidev.co.kr/deeplearning/8840]
CNN이 만들어진 연도는 1998년도 인데, 빛을 바라게된건 14년뒤인 2012년에 컴퓨터 성능이 좋아지고나서 사용이 많이됬고, 이미지넷 대회에서 빛을 바라게되면서 얀 르쿤의 논문이 빛을 받았다.
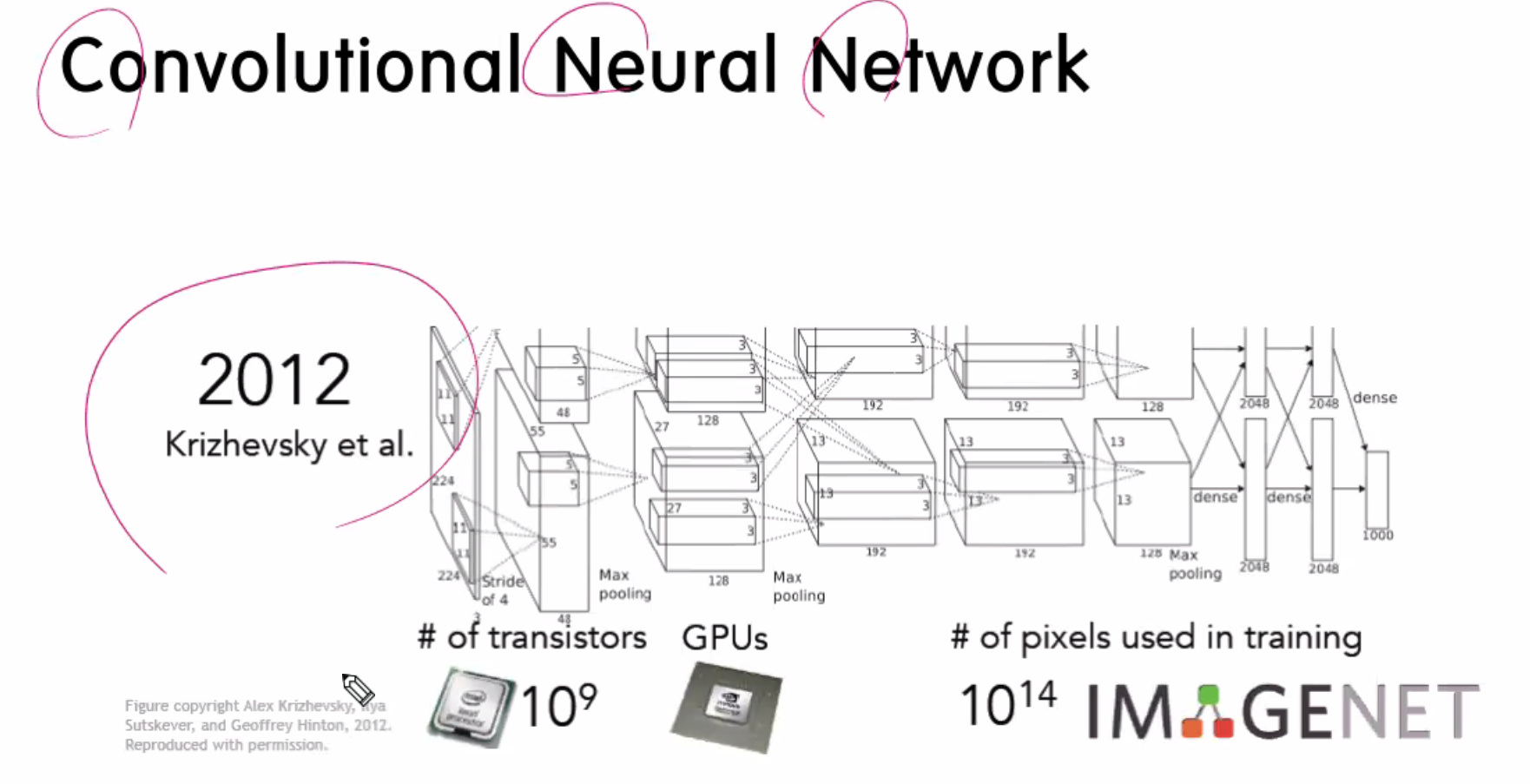

2015년 이후 이미지넷의 대회가 폐지됨,,, 이유는 인간보다 더 좋아 졌기 때문이다.
MNIST, FachilnMNIST, CIFAR10, CIFAR100, etc...... 으로 등의 종류들이 오픈데이터로 나왔다.
Classification
Classification

model, machine은 Linear로 학습을 시킨다.
인풋은 사진, 픽셀값으로 넣어주고,
아웃풋은 숫자로 받는다.
라벨을 무조건 숫자로 나온다. 0이면 고양이 1이면 강아지
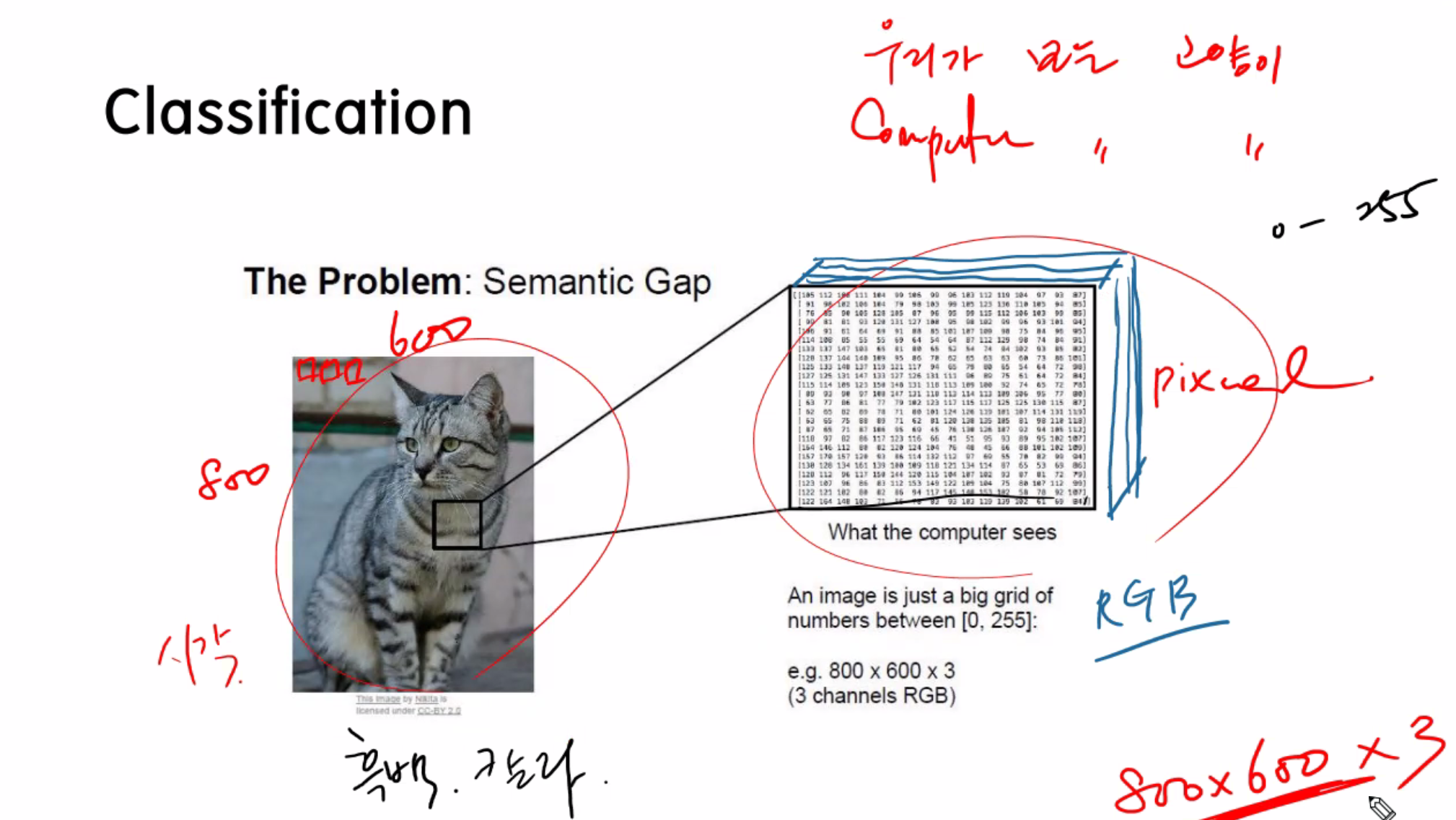
feature는 픽셀값, 즉, 픽셀값으로 라벨을 예측한다.
하지만 다양한 챌린지가 나온다... 자세나 명암.. 꼬리만 나온사진이라던지.. 배경색과 동일하다던지... 등등

이미지의 픽셀값을 인풋으로 들어간다. return으로 이미지의 라벨, 타겟이 return된다.
magic 부분에서 black box작업이 돌아간다.

학습 모델로 학습을 충분히 하고, predict, 즉 테스트 또는 예측모델로 테스트를 한다.
Nearest Neighbor
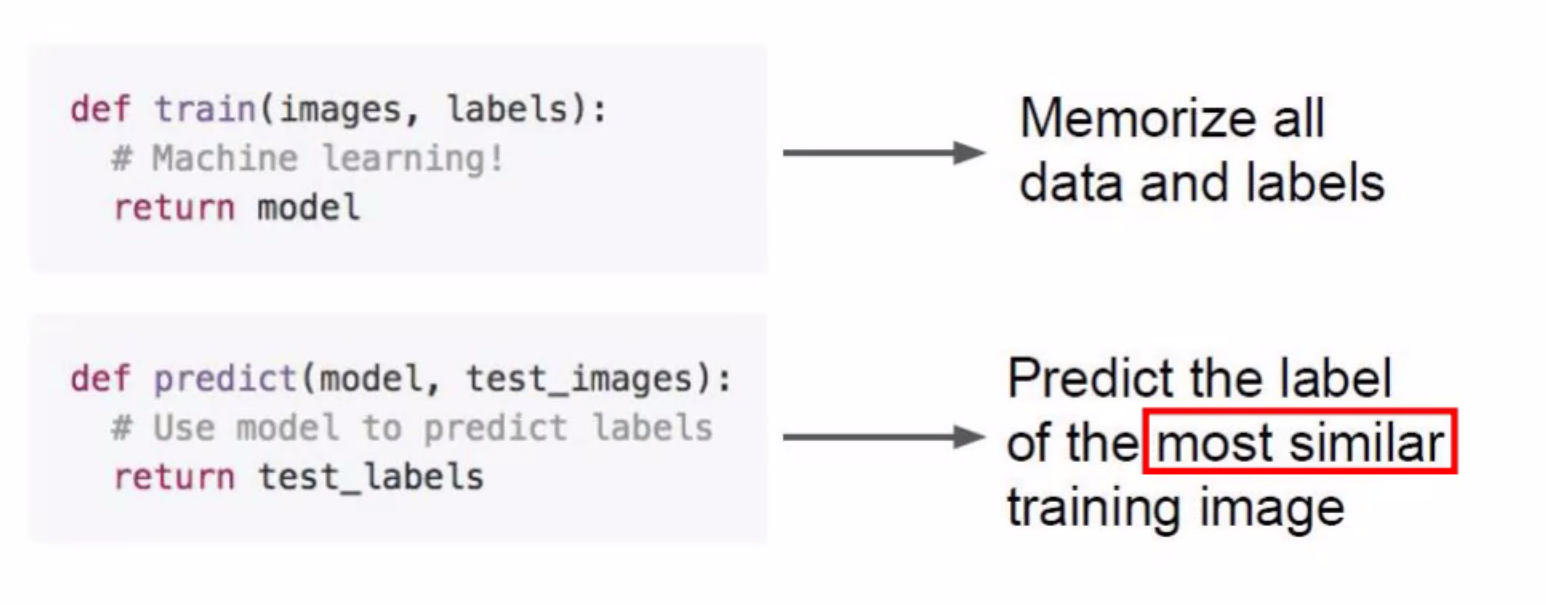
비효율 적인 부분
1. 모르는 이미지가 들어오면 5만번(기억한 이미지의 갯수)을 비교해야한다.
banchsize로 몇개씩 불러올지 조정한다.

L2 Loss는 MSE와 비슷하다...
안쓰는 가장 큰이유는 유사도가 완벽하지 않게 나온다.
필터링된사진이나,, 옮겨진 사진 등등의 작은 픽셀 변화에 민감하게 반응하기때문이다.
Cross-Validation


가장 테스트까지 traing에 추가를 시키는에 이부분이 validation test를 시키는 것이다.
Cross Vaildation
1. 가장 이상적인 DataSet 가정 >> 총 5억개의 DataSet이 있다면,,,

2. 가장 많이 사용하는 방법 이다. 주로 데이터가 없을때 Validation을 반복함으로 train의 횟수를 늘리고 train의 라벨을 validation으로 지정한뒤 validation을 번갈아 바꿔가면서 5~7번을 반복한다. (1번, 위와 같은 방법은 현실적으로 불가능함.)

Cross Validation을 사용해서 epoch을 늘려주면서 train이랑 val을 계속 바꿔서 평균 낸다.

dataset이나 computer스펙에 따라 다르게 epoch수를 정해준다.
가장 큰 특징은 Validation test 데이터를 따로 두지 않고 학습 데이터를 돌려가면서 사용한다.
Cross Validation은 train데이터가 부족할때 사용하는 기법이다

6개로 나눔.. 이것도 하이퍼 파라미터이다...... k-fold이다.



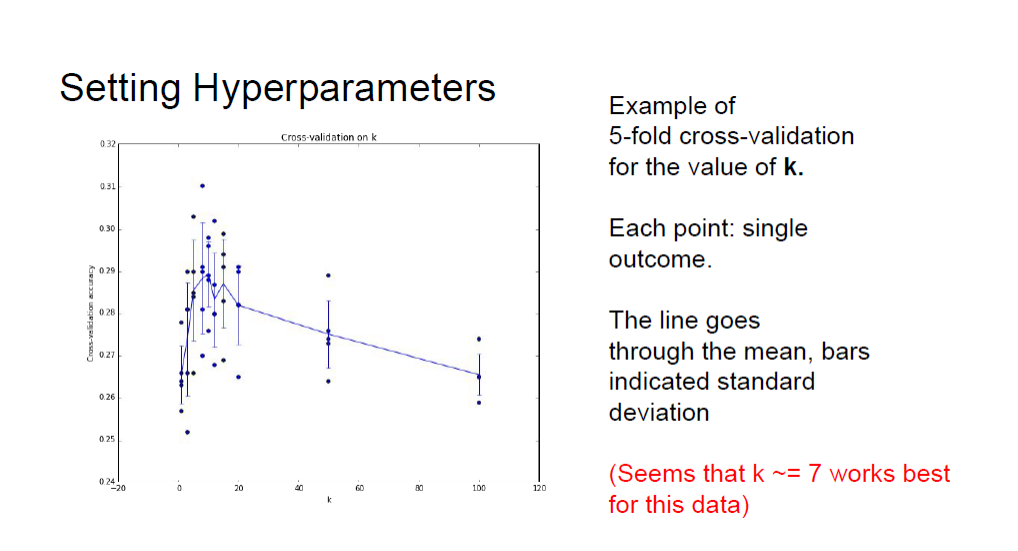
Cross Validation k-fold를 5 ~ 7 사이로 나누는 것을 권장한다.

Augmentation = Transformation 비슷.
1. 데이터를 로딩해서 불러온다
2. 교육 데이터을 증축시킨다.
3. Neural Net에서 위에서 validation한 트레이닝 데이터들을 학습시킨다.
4. Neural Net에서 테스트 데이터를 가지고 테스트를 실시한다.
5. Neural Net에서 예측한 값을 확인한다.

Linear Classifier

ANN은 레이어가 하나,
DNN은 ANN레이어가 여러개인것,
CNN은 DNN에 Convolution연산을 적용 시킨것이다.

MNIST가 연습하기 좋은 이유는 크기가 28x28, 흑백임으로...

정확도를 보면서 감을 가져야한다.
label, class, target의 갯수가 차이나는 만큼 정확도가 떨어진다.

H(x) = y이다.
행렬연산
1 번째 케이스

2 번째 케이스




Neural Net = H(x), Wx+b, f(x,W)

여기서 W은 10x3071으로 나와야한다.
b는 10x1이다. 이유는 출력값과 더한값은 같아야 하기 때문이다.




W의 shape은
1. 행 = Class의 갯수를 2차원 shape이라고 가정했을때의 행을 값.
2. 열 = Input된 3차원shape 이미지를 2차원shape으로 바꾼뒤의 행의 값
으로 설정할 수 있다.
예를 들어서 들어온 사진의 32x32x3 이라고 했을때 이것을 합하면 3072가 된다. 이숫자들을 2차원 shape으로 바꿔주면, (3072,1)의 shape의 행렬이 된다. 이 행렬의 행 값을 w의 열값으로 하고,
class가 10개가 있으면 (10,1)의 shape을 갖게 될것이다. 이때 의 행 값을 w의 행값으로 하면 최종적으로
W의 shape은 (10, 3072)의 모양이된다.

w는 맨처음에 랜덤하게 들어간다.
알아서 중요도를 주었다 보면 2.0이 중요도가 높은 부분이다.

Dog로 예측 되었다. 이것을 loss Function으로 잡아준다.
loss Function은 0에 가까울 수록 잘 나온 것이다.
loss가 높게 나오면 미분을 통해서 가중치에 적용을 시킨다.
즉 w가 이상하게 나왔으므로 결과 값이 이상하게 나온 것 이므로 책임을 부여한다.
w 값을 조정(수백번 반복)으로 가중치 값을 변경 시켜서 결과값을 다시 뽑아 본다...

학습을 안 한 상태에서 맨처음 시작하면 loss가 높게나온다 그래고 w가중치에 변경을 준다.
이렇게 되면 loss값이 점점 낮아진다. (loss값을 낮추는게 핵심이다.)
Wx + b >> 들어온 이미지의 픽셀에 각각의 중요도를 곱해준다. 후에 b(최종 값)를 더해주는데
w의 행렬은 10x3072가 되어야 연산이 가능해진다.


5만장이면 30720 x 50000 = 15억 3천6백이고 이것을 100번 반복하면
30720 x 50000 x 100 = 1.536x10^11 이 된다.
weight과 bias이 가장 중요한 역할을 한다.
Loss Function(모델이 얼마나 예측을 잘했는지를 정량화)
예측을 잘 할 수록 0에 가까워 진다.
81000 80 8 800 이 나왔다는건 공칭화(nomalization) - 스케일링이 안됨
Hinge Function


Softmax Function
Hinge function에서는 값의 극대회를 못해줘서 서로 간의 값을 A와 같이 극대화 시키는 함수가
Softmax Function을 사용해서 값을 극대화 시킬수 있다.
Hinge를 보완한게 Softmax Function이다.

예시!! Hinge -> Softmax

1. Normalization 하는법

분자 : 해당 라벨의 정확도, 분모 : 전체라벨의 정확도

+ 지수부를 붙여준다.
2. Exponential = e(2.7)는 붙여줌 2.7...


1. e 로 값을 극대화 시키고
2. 확률 값으로 변경 시켜준다.

softmax 값으로 나온 값은 예측값이다. loss 값이아니다.


1. 예측값을 추출.
2. 예측값을 softmax로 극대화 시킴
3. loss값을 알아냄.
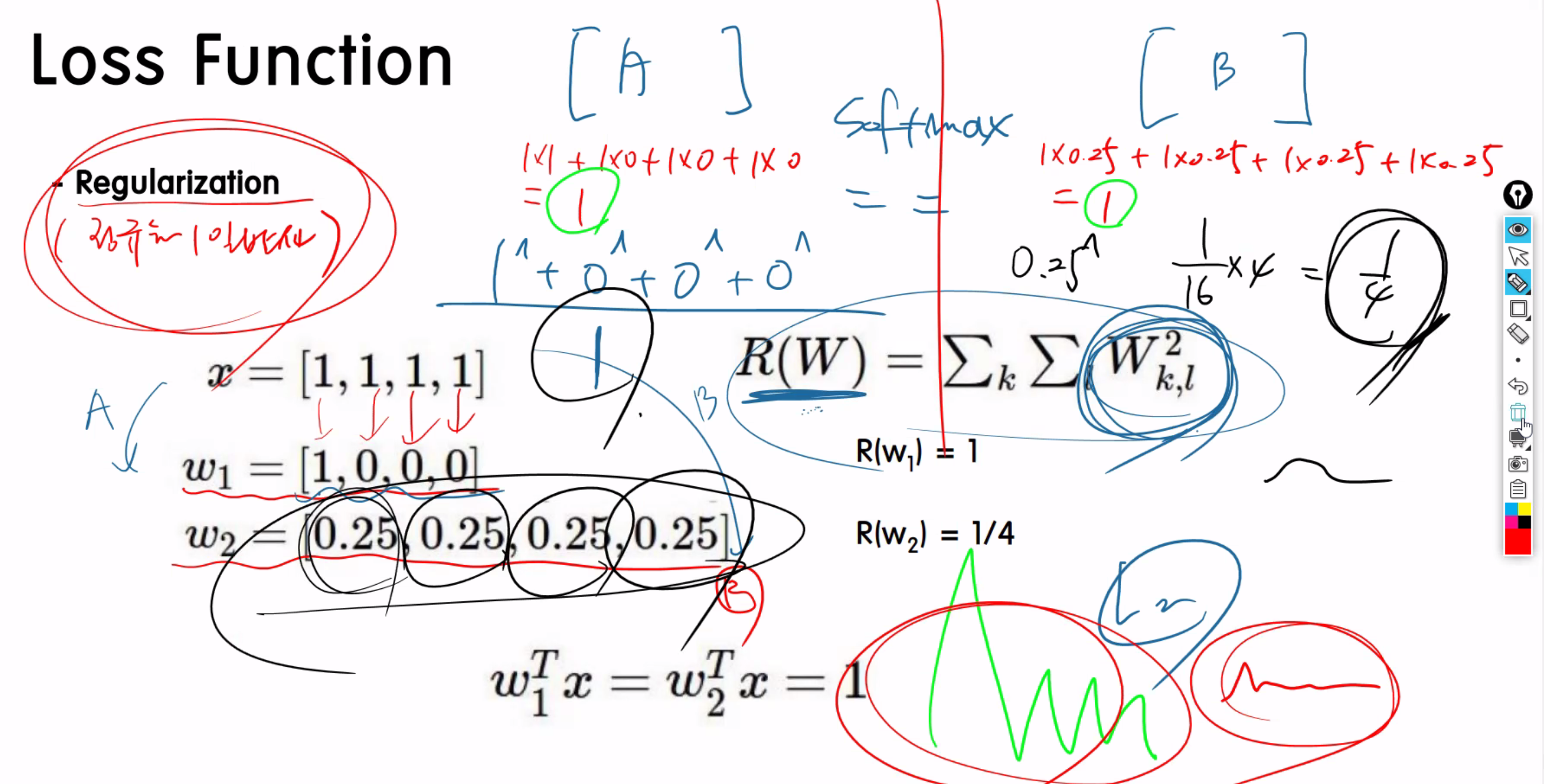
Regulariztion(정규화)

Full loss Function의 과정이다.
1. softmax Function으로 예측된 값을 극대화 시키고
2. -log(예측값) 에 넣어서 loss값을 알아낸다. (0에 가까우면 잘 예측된것.)
3. Regularization(정규화) 를 시킨다. 정규화를 시키는 방법에 대해서 알아보겠다.



각 사진을 넣으면 넣을떄마다 loss값이 나오는데 그것들을 다 더해서 갯수로 나눈값이 L(W) 모델에 대한 loss 값이다.


(예측값 - 정답 = loss)
L(W)에 W를 넣은 이유는 loss값도 W값에 따라서 바뀔수 있기 때문이다.
L(medel((w1,w1....w50000), (b1,b2,b3....b50000)))

즉 L(W)은 모델의 loss라고 보면된다.
ex)이미지를 5개 넣었다. 학습 및 예측 -> 이미지 각각에 대한 loss추출 -> 모든 loss의 평균 -> 모델에 대한 Loss : L(W)

특정 픽셀값에 가중치가 크게 잡히는 경향이 있다. >> overfitting률이 올라가고 일반화률을 떨어뜨린다.
결론) 특정 픽셀값에 대한 가중치가 너무 과도하게 잡히지 않도록 오버피팅 안되게하는 방법이 Regularization기법이다.
특정 픽셀값에 대한 가중치(W)가 높아서 오버피팅됨.

너무 굴곡졌는데 이것들 좀더 부드럽게 만들어주는 역할을 하는데 Regularization 기법이다.
L(W) 만나오면 오버피팅됬는데 이부분에 + 람다R(W)를 더해줘야한다. 람다R(W) = 는 부드럽게해준다.

softmax의값은 동일한데, R(W)을 구하면 다르게 나온다.


전체적인 로직

1. 이값은 예측값이다. 그저 DeepLearning의 predict value일 뿐,,,

2. 예측한 값(x)을 -log(x) 함수에 넣어서 loss값을 알아낸다.
3. 모델의 loss값을 알아낸다. (예측한 값의합/예측한값들의 수 = L(W))
위부분은 Foreword propogation
banch size를 100으로 하면 L(W)가 100개 나온다.
1. softmax
2. -log(x)로 모든 사진의 loss를 구한다
3. L(W)를 구하고
4. 마지막 으로 R(W)를 더해서 overfitting을 방지한다.
1. Cross Validation이란 무엇인가?
- 딥러닝 모델의 K-겹 교차검증 (K-fold Cross Validation)이라고 할 수 있다.
K-겹 교차 검증은 모든 데이터가 최소 한 번은 테스트셋으로 쓰이도록 합니다.
출처: https://3months.tistory.com/321 [Deep Play]
2. Deep Learning pipLine은 어떻게 되는가?
- 1. 데이터들을 로딩해서 불러온다.
- 1-1. 데이터들을 train, test로 나눈다.
- 1-2. train데이터에서 CrossValidation로 k-fold함수를 사용해 trian데이터와 validation데이터를 구분한다.
- 2. 데이터에 있는 CrossValidation된 데이터들을 증축 시킨다.
- 3. 증축한 데이터들을 Neural Net에 넣어서 학습시킨다.
- 4. 학습한 데이터를 기반으로한 NN를 테스트한다.
- 5. NN에서 도출된 예측값을 확인한다.
3. Linear Classification이란 무엇인가?
- 선형분류를 말한다. 선형분류로 2개의 class를 분류하면 binary classification이라고한다. 그외에 3개이상을 class로 분류할 경류는 Multinomial classification이라고 부른다.

4. 그럼 Linear Classification은 어떻게 작동 하나요?
- RGB 컬러 이미지의 차원은 32x32x3(width x height x channel)입니다. 이 3차원 shape를 가진 이미지를 1차원의 shape를 가진 모양으로 바꿔주면 3072차원의 벡터가 나옵니다.
3072차원의 벡터에 Linear Classifier의 Weight matrix와 matrix multiplication을 해주면, 우리가 분류해야 할 class 만큼의 결과 값이 나옵니다. 여기서 class의 총 개수가 10개 이므로, Wx의 결과값은 10개가 나오게 되고, 여기에 bias 텀을 더해주게 되면, Classifier가 예측한 값이 나오게 됩니다.
즉, 이미지를 strecth(3차원 shape를 1차원 shape로)한 뒤, Weight matrix와 곱한 뒤 bias를 더해 나온 최종 score로 표현해 줍니다.
Linear Classifier가 내놓은 결과 값에 대해 제대로 분류를 했나 평가를 하기 위해서, 정답 레이블과 비교를 합니다. 비교를 해주는 함수가 바로 Loss 함수 입니다.

5. 어떻게 하면 loss 함수를 통해 weight들을 업데이트 할 수 있을까요?

forword propagation
1. 이미지의 픽셀값을 2차원구조로 바꿈 > 2. Neural Net 에서 연산작업 > 3. 예측값 y 도출 > 4. softmax > 6. -log(x) > 7. loss들을 미분,,, (loss들을 더한값 / loss들의 갯수)> 8. L(W) > 9. L(W) + R(W) 가중치를 정규화시킴.
back propagation
back 에서는 w의 가중치를 update를 시켜서 L(W)+R(W)의 값을 계속적으로 업데이트 시킨다.
Loss function 및 Optimization 참고 블로그 chacha95.github.io/2018-11-17-Deeplearning1_5/
Optimization
이번 포스트에서는 weight들이 어떻게 조정 되는지 알아 봅시다. 편의상 weight와 bias를 weight라고 묶어서 말하겠습니다. 미분포스트를 읽고, CS231n Backpropagation강의를 듣고 읽으시는 걸 추천드립니다
chacha95.github.io
미분 참고 블로그 = chacha95.github.io/2018-11-01-numerical/
수치미분과 해석미분 그리고 그래디언트
미분에 대한 간략한 설명 당신이 마라톤 선수고 처음부터 10분에 2km씩 달렸다고 가정해봅시다. 이 때 속도는 2/10 = 0.2(km/분)입니다. 달린거리가 시간에 대해 얼마나 변화 했는가를 계산했습니다.
chacha95.github.io
'workSpace > PYTHON' 카테고리의 다른 글
| [DL] Basic analysis of using SGD Optimizer with code. (1) (0) | 2021.01.28 |
|---|---|
| [DL] Back Propagation (0) | 2021.01.28 |
| [DL] Knowledge and Algorithm Overview (0) | 2021.01.27 |
| [ML] Collaborative Filtering (추천 협업 시스템) (0) | 2021.01.26 |
| [DL] Ensemble, Matrix Confusion and Linear Regression (0) | 2021.01.25 |